
Examples of A) Degree centrality, B) Closeness centrality, C)
Betweenness centrality, D) Eigenvector centrality, E) Katz centrality and F) Alpha centrality of the same graph.
Within the scope of graph theory and network analysis, there are various types of measures of the centrality of a vertex within a graph that determine the relative importance of a vertex within the graph (e.g. how influential a person is within a social network, or, in the theory of space syntax, how important a room is within a building or how well-used a road is within an urban network). Many of the centrality concepts were first developed in social network analysis, and many of the terms used to measure centrality reflect their sociological origin.[1]
There are four measures of centrality that are widely used in network analysis: degree centrality, betweenness, closeness, and eigenvector centrality. For a review as well as generalizations to weighted networks, see Opsahl et al. (2010).[2]
Degree centrality
Historically first and conceptually simplest is degree centrality, which is defined as the number of links incident upon a node (i.e., the number of ties that a node has). The degree can be interpreted in terms of the immediate risk of a node for catching whatever is flowing through the network (such as a virus, or some information). In the case of a directed network (where ties have direction), we usually define two separate measures of degree centrality, namely indegree and outdegree. Accordingly, indegree is a count of the number of ties directed to the node and outdegree is the number of ties that the node directs to others. When ties are associated to some positive aspects such as friendship or collaboration, indegree is often interpreted as a form of popularity, and outdegree as gregariousness.
The degree centrality of a vertex  , for a given graph
, for a given graph  with
with  vertices and
vertices and  edges, is defined as
edges, is defined as

Calculating degree centrality for all the nodes in a graph takes  in a dense adjacency matrix representation of the graph, and for edges takes
in a dense adjacency matrix representation of the graph, and for edges takes  in a sparse matrix representation.
in a sparse matrix representation.
Sometimes the interest is in finding the centrality of a graph within a graph. The definition of centrality on the node level can be extended to the whole graph. Let  be the node with highest degree centrality in
be the node with highest degree centrality in 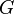 . Let
. Let  be the
be the  node connected graph that maximizes the following quantity (with
node connected graph that maximizes the following quantity (with  being the node with highest degree centrality in
being the node with highest degree centrality in  ):
):

Correspondingly, the degree centrality of the graph is as follows:
![C_D(G)= \frac{\displaystyle{\sum^{|V|}_{i=1}{[C_D(v*)-C_D(v_i)]}}}{H}](https://wiki.edunitas.com/_buku_manual/_baca_blob.php?book=lain&td=3&kodegb=755c1a4f0f1f33c8fbb345d7c4187c7d.png)
The value of  is maximized when the graph contains one central node to which all other nodes are connected (a star graph), and in this case
is maximized when the graph contains one central node to which all other nodes are connected (a star graph), and in this case  .
.
Closeness centrality
In connected graphs there is a natural distance metric between all pairs of nodes, defined by the length of their shortest paths. The farness of a node s is defined as the sum of its distances to all other nodes, and its closeness is defined as the inverse of the farness.[3] Thus, the more central a node is the lower its total distance to all other nodes. Closeness can be regarded as a measure of how fast it will take to spread information from s to all other nodes sequentially.[4]
In the classic definition of the closeness centrality, the spread of information is modeled by the use of shortest paths. This model might not be the most realistic for all types of communication scenarios. Thus, related definitions have been discussed to measure closeness, like the random walk closeness centrality introduced by Noh and Rieger (2004). It measures the speed with which randomly walking messages reach a vertex from elsewhere in the network—a sort of random-walk version of closeness centrality.[5]
The information centrality of Stephenson and Zelen (1989) is another closeness measure, which bears some similarity to that of Noh and Rieger. In essence it measures the harmonic mean length of paths ending at a vertex i, which is smaller if i has many short paths connecting it to other vertices.[6]
Note that by definition of graph theoretic distances, the classic closeness centrality of all nodes in an unconnected graph would be 0. In a work by Dangalchev (2006) relating network vulnerability, the definition for closeness is modified such that it can be calculated more easily and can be also applied to graphs which lack connectivity:[7]

Another extension to networks with disconnected components has been proposed by Opsahl (2010).[8]
Betweenness centrality

Hue (from red=0 to blue=max) shows the node betweenness.
Betweenness is a centrality measure of a vertex within a graph (there is also edge betweenness, which is not discussed here). Betweenness centrality quantifies the number of times a node acts as a bridge along the shortest path between two other nodes. It was introduced as a measure for quantifying the control of a human on the communication between other humans in a social network by Linton Freeman.[9] In his conception, vertices that have a high probability to occur on a randomly chosen shortest path between two randomly chosen vertices have a high betweenness.
The betweenness of a vertex in a graph with  vertices is computed as follows:
vertices is computed as follows:
1. For each pair of vertices (s,t), compute the shortest paths between them.
2. For each pair of vertices (s,t), determine the fraction of shortest paths that pass through the vertex in question (here, vertex v).
3. Sum this fraction over all pairs of vertices (s,t).
More compactly the betweenness can be represented as:[10]

where  is total number of shortest paths from node
is total number of shortest paths from node  to node
to node  and
and  is the number of those paths that pass through . The betweenness may be normalised by dividing through the number of pairs of vertices not including v, which for directed graphs is
is the number of those paths that pass through . The betweenness may be normalised by dividing through the number of pairs of vertices not including v, which for directed graphs is  and for undirected graphs is
and for undirected graphs is  . For example, in an undirected star graph, the center vertex (which is contained in every possible shortest path) would have a betweenness of (1, if normalised) while the leaves (which are contained in no shortest paths) would have a betweenness of 0.
. For example, in an undirected star graph, the center vertex (which is contained in every possible shortest path) would have a betweenness of (1, if normalised) while the leaves (which are contained in no shortest paths) would have a betweenness of 0.
From a calculation aspect, both betweenness and closeness centralities of all vertices in a graph involve calculating the shortest paths between all pairs of vertices on a graph, which requires  time with the Floyd–Warshall algorithm. However, on sparse graphs, Johnson's algorithm may be more efficient, taking
time with the Floyd–Warshall algorithm. However, on sparse graphs, Johnson's algorithm may be more efficient, taking  time. In the case of unweighted graphs the calculations can be done with Brandes' algorithm[10] which takes
time. In the case of unweighted graphs the calculations can be done with Brandes' algorithm[10] which takes  time. Normally, these algorithms assume that graphs are undirected and connected with the allowance of loops and multiple edges. When specifically dealing with network graphs, oftentimes graphs are without loops or multiple edges to maintain simple relationships (where edges represent connections between two people or vertices). In this case, using Brandes' algorithm will divide final centrality scores by 2 to account for each shortest path being counted twice.[10]
time. Normally, these algorithms assume that graphs are undirected and connected with the allowance of loops and multiple edges. When specifically dealing with network graphs, oftentimes graphs are without loops or multiple edges to maintain simple relationships (where edges represent connections between two people or vertices). In this case, using Brandes' algorithm will divide final centrality scores by 2 to account for each shortest path being counted twice.[10]
Eigenvector centrality
Eigenvector centrality is a measure of the influence of a node in a network. It assigns relative scores to all nodes in the network based on the concept that connections to high-scoring nodes contribute more to the score of the node in question than equal connections to low-scoring nodes. Google's PageRank is a variant of the Eigenvector centrality measure.[11] Another closely related centrality measure is Katz centrality.
Using the adjacency matrix to find eigenvector centrality
For a given graph with number of vertices let  be the adjacency matrix, i.e.
be the adjacency matrix, i.e.  if vertex is linked to vertex , and
if vertex is linked to vertex , and  otherwise. The centrality score of vertex can be defined as:
otherwise. The centrality score of vertex can be defined as:

where  is a set of the neighbors of and
is a set of the neighbors of and  is a constant. With a small rearrangement this can be rewritten in vector notation as the eigenvector equation
is a constant. With a small rearrangement this can be rewritten in vector notation as the eigenvector equation

In general, there will be many different eigenvalues for which an eigenvector solution exists. However, the additional requirement that all the entries in the eigenvector be positive implies (by the Perron–Frobenius theorem) that only the greatest eigenvalue results in the desired centrality measure.[12] The  component of the related eigenvector then gives the centrality score of the vertex in the network. Power iteration is one of many eigenvalue algorithms that may be used to find this dominant eigenvector.[11] Furthermore, this can be generalized so that the entries in A can be real numbers representing connection strengths, as in a stochastic matrix.
component of the related eigenvector then gives the centrality score of the vertex in the network. Power iteration is one of many eigenvalue algorithms that may be used to find this dominant eigenvector.[11] Furthermore, this can be generalized so that the entries in A can be real numbers representing connection strengths, as in a stochastic matrix.
Katz centrality and PageRank
Katz centrality [13] is a generalization of degree centrality. Degree centrality measures the number of direct neighbors, and Katz centrality measures the number of all nodes that can be connected through a path, while the contribution of a distant node is penalized by an attenuation factor  . Mathematically, it is defined as
. Mathematically, it is defined as  .
.
Katz centrality can be viewed as a variant of eigenvector centrality. Another form of Katz centrality is  Compared to the expression of eigenvector centrality,
Compared to the expression of eigenvector centrality,  is replaced by
is replaced by  .
.
It is shown that [14] the principal eigenvector (associated with the largest eigenvalue of  , the adjacency matrix) is the limit of Katz centrality as
, the adjacency matrix) is the limit of Katz centrality as  approaches
approaches  from below.
from below.
PageRank satisfies the following equation  where
where  is the number of neighbors of node
is the number of neighbors of node  (or number of outbound links in a directed graph). Compared to eigenvector centrality and Katz centrality, one major difference is the scaling factor
(or number of outbound links in a directed graph). Compared to eigenvector centrality and Katz centrality, one major difference is the scaling factor  . Another difference between PageRank and eigenvector centrality is that the PageRank vector is a left hand eigenvector (note the factor
. Another difference between PageRank and eigenvector centrality is that the PageRank vector is a left hand eigenvector (note the factor  has indices reversed).[15]
has indices reversed).[15]
Definition and characterization of centrality indices
Next to the above named classic centrality indices, there are dozens of other more specialized centrality indices. Despite its intuitive notion there is not yet a definition or characterization of centrality indices which captures all of them.[16] A very loose definition of a centrality index is the following:
A centrality index is a real-valued function on the nodes of a graph. It is a structural index, i.e., if and are two isomorphic graphs and  is the mapping from the vertex set
is the mapping from the vertex set  of to V(H), then the centrality of a vertex of must be the same as the centrality of
of to V(H), then the centrality of a vertex of must be the same as the centrality of  in . Conventionally, the higher the centrality index of a node, the higher its perceived centrality in the graph.[17] This definition comprises all classic centrality measures but not all measures that fulfill this definition would be accepted as centrality indices.
in . Conventionally, the higher the centrality index of a node, the higher its perceived centrality in the graph.[17] This definition comprises all classic centrality measures but not all measures that fulfill this definition would be accepted as centrality indices.
Borgatti and Everett summarize that centrality indices measure the position of a node along a predefined set of walks. They characterize centrality indices along four dimensions: the set of walks, whether the length or the number of these walks is considered, the position of the node on the walks (at the start=radial; in the middle=medial), and how the numbers assigned to the paths are summarized in the measure (average, median, weighted sum, ...).[16] This leads to a characterization by the way a centrality index is calculated. In a different characterization, Borgatti differentiates the centrality indices by what type of paths they consider and which type of network flow they imply.[18] The latter characterizes the centrality indices by the quality with which they predict which node is most central for a given network flow process. This characterization thus provides guidance on when to use which centrality index.
Centralization
The centralization of any network is a measure of how central its most central node is in relation to how central all the other nodes are.[19] The general definition of centralization for non-weighted networks was proposed by Linton Freeman (1979). Centralization measures then (a) calculate the sum in differences in centrality between the most central node in a network and all other nodes; and (b) divide this quantity by the theoretically largest such sum of differences in any network of the same degree.[19] Thus, every centrality measure can have its own centralization measure. Defined formally, if  is any centrality measure of point
is any centrality measure of point  , if
, if  is the largest such measure in the network, and if
is the largest such measure in the network, and if  is the largest sum of differences in point centrality
is the largest sum of differences in point centrality  for any graph of with the same number of nodes, then the centralization of the network is:[19]
for any graph of with the same number of nodes, then the centralization of the network is:[19]

See also
Notes and references
- ^ Newman, M.E.J. 2010. Networks: An Introduction. Oxford, UK: Oxford University Press.
- ^ Opsahl, Tore; Agneessens, Filip; Skvoretz, John (2010). "Node centrality in weighted networks: Generalizing degree and shortest paths". Social Networks 32 (3): 245. doi:10.1016/j.socnet.2010.03.006.
- ^ Sabidussi, G. (1966) The centrality index of a graph. Psychometrika 31, 581–603.
- ^ M.E.J. Newman (2005), A measure of betweenness centrality based on random walks 27, pp. 39–54, arXiv:cond-mat/0309045, doi:10.1016/j.socnet.2004.11.009 Papercore summary http://papercore.org/Newman2005.
- ^ J. D. Noh and H. Rieger, Phys. Rev. Lett. 92, 118701 (2004).
- ^ Stephenson, K. A. and Zelen, M., 1989. Rethinking centrality: Methods and examples. Social Networks 11, 1–37.
- ^ Dangalchev Ch., Residual Closeness in Networks, Phisica A 365, 556 (2006).
- ^ Tore Opsahl. Closeness centrality in networks with disconnected components.
- ^ Freeman, Linton (1977). "A set of measures of centrality based upon betweenness". Sociometry 40: 35–41.
- ^ a b c Brandes, Ulrik (2001). "A faster algorithm for betweenness centrality" (PDF). Journal of Mathematical Sociology 25: 163–177. Retrieved 10.11.2011. Paperore summary http://papercore.org/Brandes2001
- ^ a b http://www.ams.org/samplings/feature- column/fcarc-pagerank
- ^ M. E. J. Newman. The mathematics of networks (PDF). Retrieved 2006-11-09.
- ^ Katz, L. 1953. A New Status Index Derived from Sociometric Index. Psychometrika, 39–43.
- ^ Bonacich, P., 1991. Simultaneous group and individual centralities. Social Networks 13, 155–168.
- ^ How does Google rank webpages? 20Q: About Networked Life
- ^ a b Borgatti, Stephen P.; Everett, Martin G. (2005). "A Graph-Theoretic Perspective on Centrality". Social Networks (Elsevier) 28: 466–484. doi:10.1016/j.socnet.2005.11.005.
- ^ Koschützki, Dirk; Katharina A. Lehmann, Leon Peeters, Stefan Richter, Dagmar Tenfelde-Podehl, Oliver Zlotowski (2005). "Centrality Indices". In Ulrik Brandes, Thomas Erlebach. Network Analysis – Methodological Foundations. LNCS 3418. Springer Verlag, Heidelberg, Germany. pp. 16–60. ISBN 978-3-540-24979-5.
- ^ Stephen P. Borgatti (2005). "Centrality and Network Flow". Social Networks (Elsevier) 27: 55–71.
- ^ a b c Freeman, L. C. (1979). Centrality in social networks: Conceptual clarification. Social Networks, 1(3), 215–239.
Further reading
- Freeman, L. C. (1979). Centrality in social networks: Conceptual clarification. Social Networks, 1(3), 215–239.
- Sabidussi, G. (1966). The centrality index of a graph. Psychometrika, 31 (4), 581–603.
- Freeman, L. C. (1977). A set of measures of centrality based on betweenness. Sociometry 40, 35–41.
- Koschützki, D.; Lehmann, K. A.; Peeters, L.; Richter, S.; Tenfelde-Podehl, D. and Zlotowski, O. (2005) Centrality Indices. In Brandes, U. and Erlebach, T. (Eds.) Network Analysis: Methodological Foundations, pp. 16–61, LNCS 3418, Springer-Verlag.
- Bonacich, P. (1987). Power and Centrality: A Family of Measures, The American Journal of Sociology, 92 (5), pp 1170–1182.
External links













